Em xin giới thiệu chủ đề này để khi bác nào có làm về Marketing in Banking có thể tham khảo, chủ đề này đã được cộng đồng ML viết nhiều, em tổng hợp lại và em để đường link cho các bác tham khảo.
https://github.com/topics/bank-marketing-analysis
Đề bài đặt ra là Team của bạn đang cần huy động vốn từ các Khách hàng cá nhân.
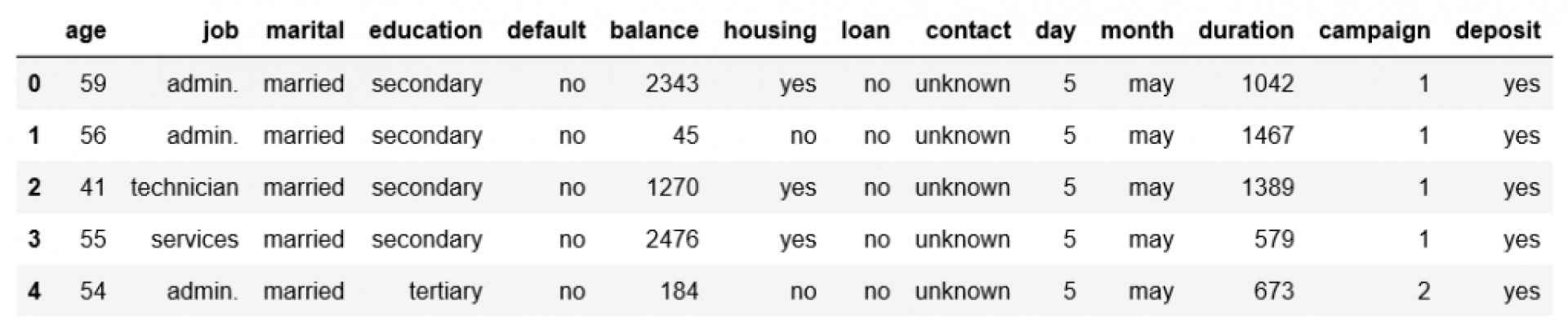
Chúng ta có bảng dữ liệu thô từ chiến dịch “Huy động vốn” lần trước như sau:
Bảng dữ liệu này có hơn 11.000 dòng, và 14 cột như trên, tương ứng với việc ta có hơn 11000 khách hàng.
Thông tin từ bảng dữ liệu ta biết được, Tuổi, Nghề nghiệp, Số dư tài khoản, có đang vay tiền Mua nhà hay vay cá nhân ko, và người đó có đang gửi tiết kiệm hay ko. Mục tiêu của chúng ta là tìm ra những yếu tố trên, yếu tố nào quan trọng trong việc quyết định người đó có gửi tiết kiệm hay ko thông qua cột Deposit là "yes" hay "no"
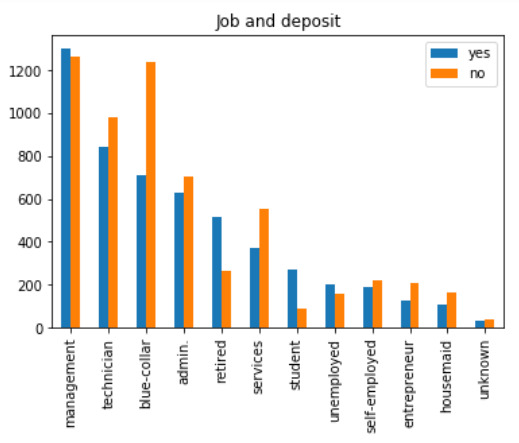
Khảo sát ban đầu từ bảng dữ liệu ta thấy người làm trong ngành Dịch vụ, Công nhân thường có xu hướng ko gửi tiết kiệm. Trong khi những người đã Nghỉ hưu thường có xu hướng gửi tiết kiệm cao nhất.
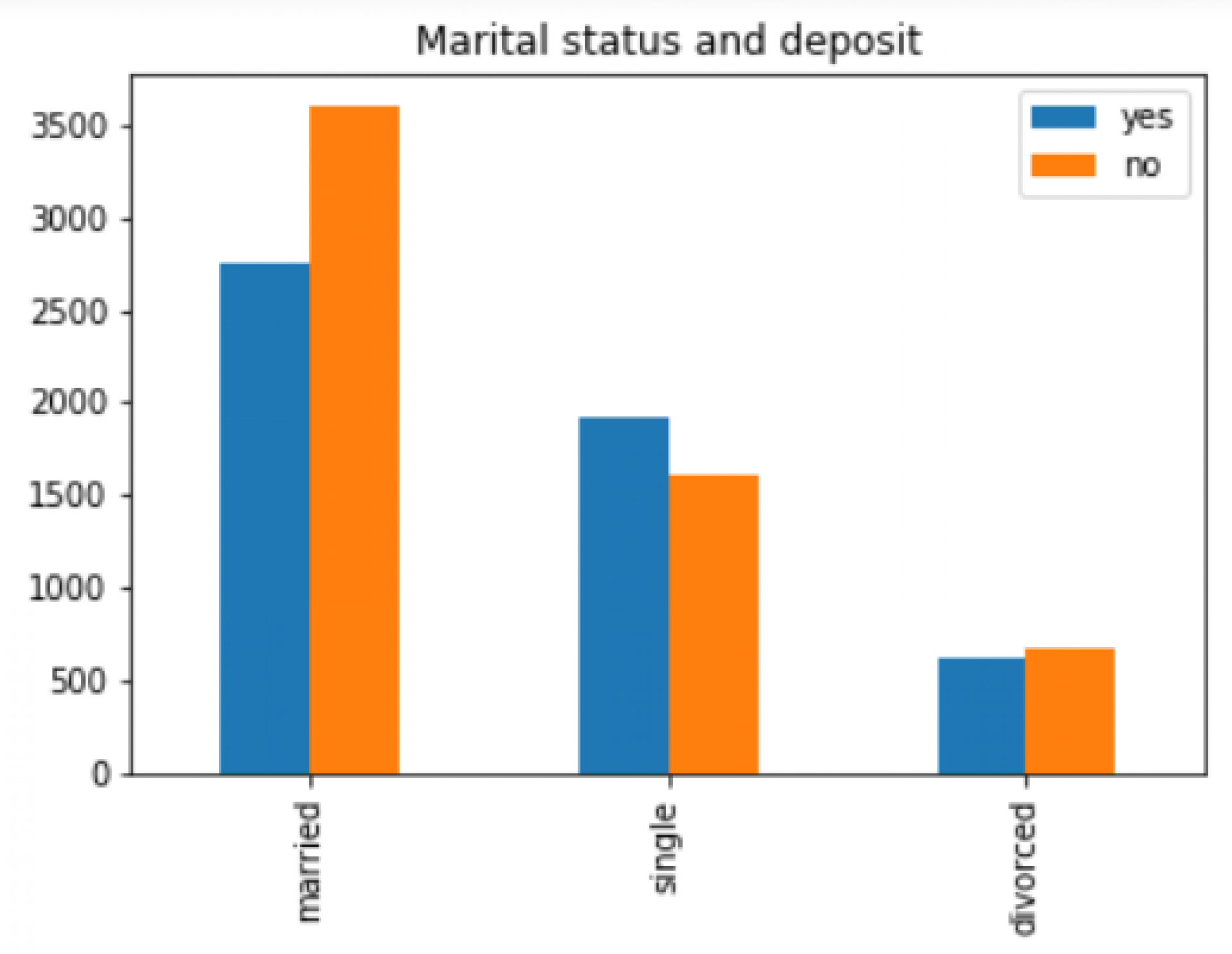
Tình trạng hôn nhân cung có phần ảnh hưởng đến việc người đó có xu hướng gửi tiết kiêm hay ko, thì với những người độc thân hay đã ly dị thường có xu hướng gửi tiết kiêm cao hơn những cặp vợ chồng.
Mục tiêu là ta tìm được 1 model đi qua các đặc điểm trong bang dữ liệu và dự báo được là người đó có Gửi tiết kiệm hay ko.
Và từ đó rút ra được đặc điểm nào sẽ mang tính chat quyết định quan trọng nhất.
Khi đã xử lý dữ liệu thô và chạy ra model thì ta rút ra dc các đặc điểm quan trọng sau:
.
Từ kết quả model ta có được thông tin Số dư tài khoản và tuổi của khách hàng là 2 yếu tố quyết định
Như vậy để xác suất trên 50% Khách hang sẽ chap nhận gửi tiết kiệm thì:
Số dư tài khoản của Khách hang nên từ 1490usd trở lên.
Độ Tuổi dưới 31 tuổi, hoặc trên 56 tuổi.
Ngoài ra số cuộc gọi đến Khách hàng dưới 4 cuộc gọi, vì từ 5 cuộc gọi trở lên thì Khách hang thường có xu hướng từ chối gửi tiết kiệm.
Như vậy công việc của Team sẽ thuận lợi hơn khi tiếp thị chiến dịch "Huy động vốn" tập trung cho những Khách hàng có đặc điểm trên.
Đây là kết quả rút ra được từ data đã được Public trên mạng và ở 1 bank nào đó của nước ngoài. Nếu ở Việt Nam và có data thì kết quả phân tích của chúng ta sẽ ra khác nhưng con đường phân tích thì tương tự.