Bác @insight cũng đang làm trong bank và dùng ML trong công việc phải ko, em cũng thích data trong bank lắm mà chưa có cơ hội vào.dùng R quá sâu, quá kỹ thuật và với mô hình thực tế thì không dễ để code đâu, cái này dành cho mấy bạn kỹ thuật.
Hướng tới dùng tool để sử dụng, vận hành linh hoạt và quan trọng là giải quyết được bài toán thực tế của ngân hàng hoặc doanh nghiệp thì mới là cái nên làm.
Thử tiếp mấy dữ liệu khác coi, iris quá dễ rồi. Thử Thyroid , E.coli, Glass coi sao ?Là 30/70 đó bác, mà em nhận thấy R_squared của nó tốt cũng phần lớn là do inputs nó dễ đoán labels quá, có khi mình nhìn mắt cũng đoán dc.
Bác Linh chắc làm việc trong lĩnh vực ML này cũng lâu rồi à, cụ thể hơn 1 tí cho em biết về cv bác đang làm dc ko?Thử tiếp mấy dữ liệu khác coi, iris quá dễ rồi. Thử Thyroid , E.coli, Glass coi sao ?
Chẩn đoán hư hỏng ổ lăn, dùng svm sau khi đã tối ưu hoá thông số. Nc từ 2011 thôi. Giờ cũng chán rồi.Bác Linh chắc làm việc trong lĩnh vực ML này cũng lâu rồi à, cụ thể hơn 1 tí cho em biết về cv bác đang làm dc ko?
Bác @insight cũng đang làm trong bank và dùng ML trong công việc phải ko, em cũng thích data trong bank lắm mà chưa có cơ hội vào.
không bác, em là thằng bán cái giải pháp này vào cho mấy ông đó
Vậy là bác có nhiều kinh nghiệm trong lĩnh vực này rồi.không bác, em là thằng bán cái giải pháp này vào cho mấy ông đó
Tối nay hoặc ngày mai em sẽ trình bày chi tiết từng bước trong quá trình xử lý dữ liệu lên đây, có gì nhờ bác và các bác khác xem góp ý giúp em nhé.
Vậy là bác có nhiều kinh nghiệm trong lĩnh vực này rồi.
Tối nay hoặc ngày mai em sẽ trình bày chi tiết từng bước trong quá trình xử lý dữ liệu lên đây, có gì nhờ bác và các bác khác xem góp ý giúp em nhé.
Code như bác em chịu, em bỏ code được 10 năm rồi - cái làm mô hình thì em dùng https://rapidminer.com/ rồi phần còn lại là present dữ liêu này lên, có thể dùng luôn Raidminer hoặc em dùng Tableau (www.tableau.com). Repidminer bản studio có free đó, đem xuống mà dùng bác, nó mới có khả năng giải quyết các bài toán được gọi là ML của doanh nghiệp.
Rapidminer gần như đứng top về ML và DS plarform trong nhiều năm liền https://rapidminer.com/resource/gartner-magic-quadrant-data-science-platforms/
Em làm chi tiết các bước xử lý dữ liệu trước khi chạy mô hình, để các bác nào muốn tìm hiểu về nó sẽ có cái nhìn rõ hơn, mặt khác cũng là dịp để các bác đi trước hướng dẫn em thêm.
Kỳ này em sử dụng bộ data full hơn bộ trước, các bước xử lý là em tổng hợp được những ý hay của nhiều người phân tích trên mạng thành 1 bài riêng mà em cho rằng nó hợp lý hơn.
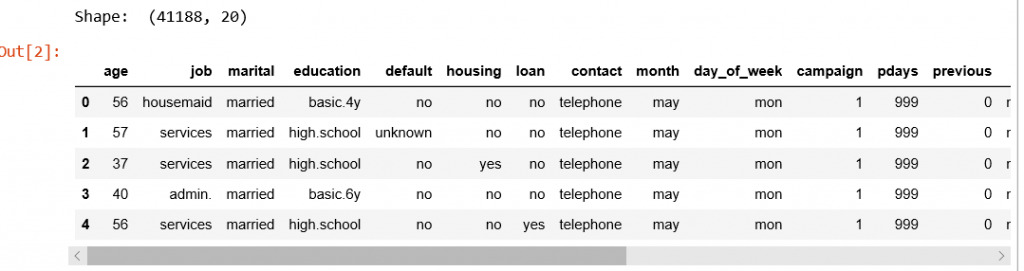
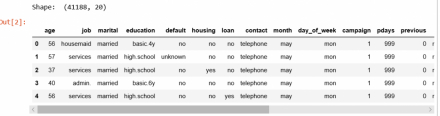
Đầu tiên là bộ data có hơn 41k dòng và 20 cột, Output vẫn là cột deposit mà các phần tử trong cột này chỉ có 2 giá trị là yes hay no, yes có ý nghĩa Khách hàng đồng ý gửi Tiết kiệm, no thì ngược lại

Sau khi check qua xem có ô nào bị trống ko có dữ liệu ko, và các Hàng của Cột có bằng nhau ko thì data thỏa mãn.
Tuy nhiên nhìn qua bảng data ta thấy có những ô là unknown, có nghĩa là ngay ô này ko có dữ liệu, nó tương đương với 1 ô trắng mà ta phải cần xử lý nó.
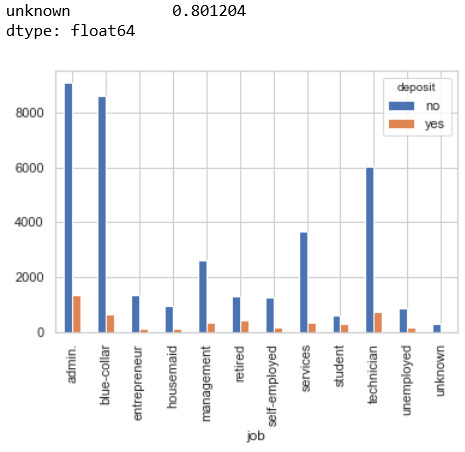
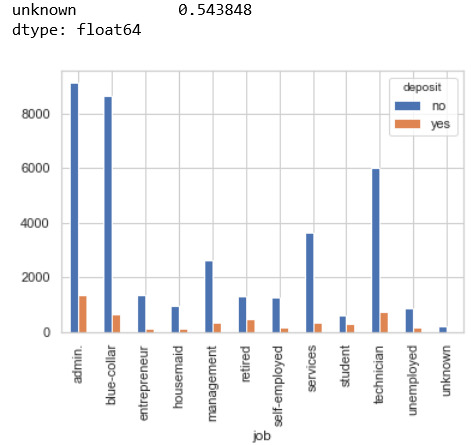
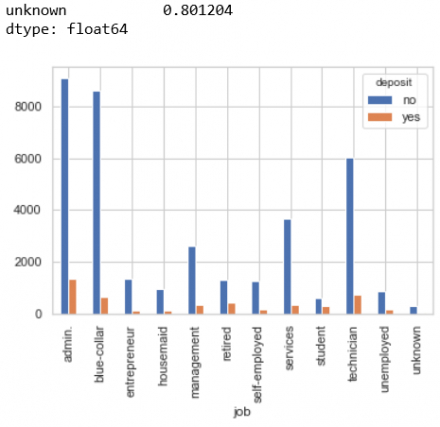
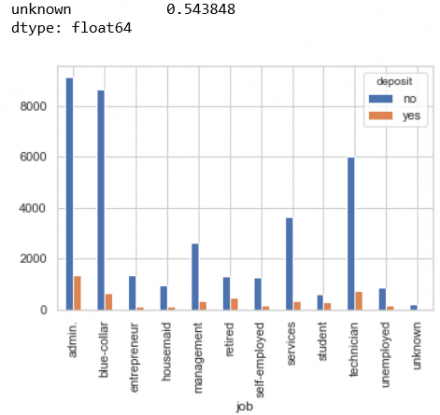
Em sẽ kiểm tra qua cột Job xem có bao nhiêu ô có unknown thì ra dc kết quả sau

Trong hình ta thấy các ô unknown trong cột Job này chiếm 0.8%, con số ko lớn lắm, tuy nhiên data là của quý nên ta ko tùy tiện loại bỏ các ô unknown này mà nên xử lý nó.
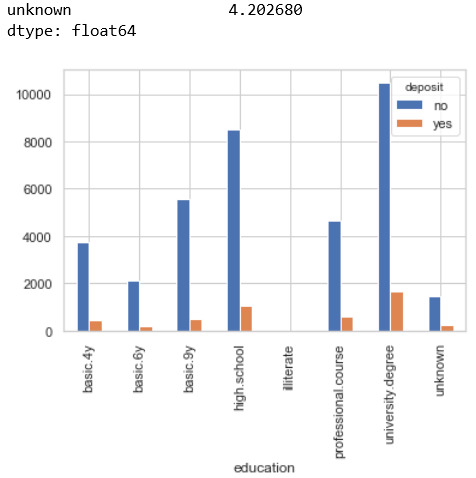
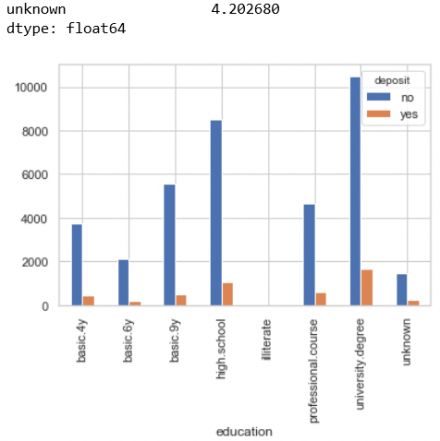
Em check tiếp cột education xem có bao nhiêu % là ô unknown

Kết quả là 4.2%, con số này bắt đầu thấy to to rồi vì mình có hơn 41k dòng, nếu ta quyết định xóa các ô unknown này thì ta sẽ mất đi hơn 1700 dòng dữ liệu, vì vậy ta cần xử lý nó mà ko xóa nó đi.
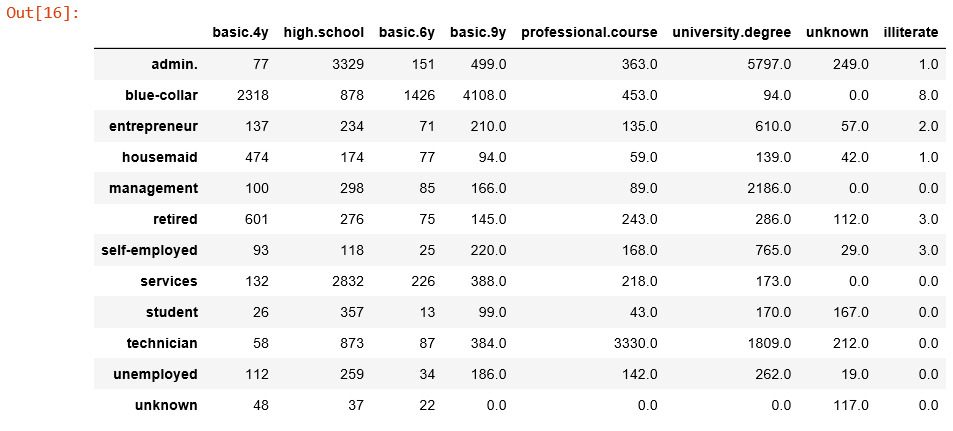
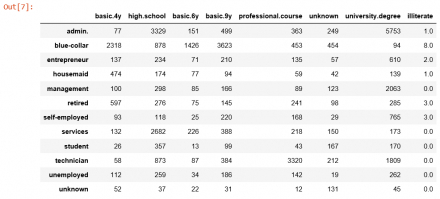
Đến đây thì ta check xem giữa Job và education có mối quan hệ như thế nào, lúc này mình check bảng ma trận của Job và education như sau:

Từ data ban đầu ta vẽ ra được bảng chỉ có Job và education, quan sát bảng trên ta thấy admin, management hầu hết là những người có bằng đại học, technician thì có bằng professional.course, service thì chủ yếu là high.school, từ đó mới có ý tưởng là khi ta biết Job(admin, management, technician, service) nhưng ko biết education thì ta có thể dự đoán ra người đó có education gì.
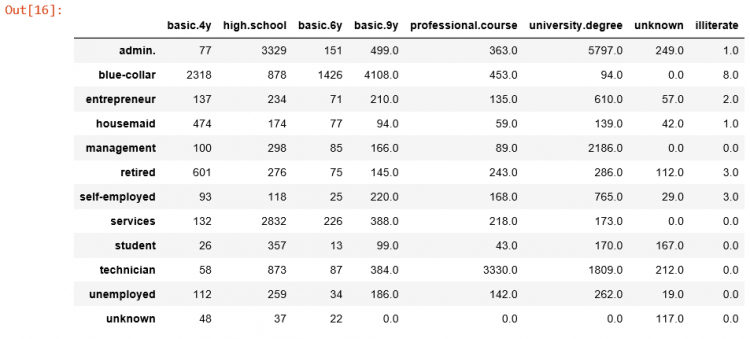
Vì vậy ở bước này quan sát cột unknown từ bảng trên thì ta cũng có thể tách 1 phần unknown vào các ô tương ứng, tương tự là ở dòng unknown cũng vậy.
Sau khi làm ta có kết quả sau:

Quan sát ta thấy cả dòng và cột unknow đã xuất hiện các phần tử 0, đây chính là các phần tử mà ta đã tận dụng và chuyển qua các ô tương ứng.Bây giờ ta checjk lại xem trong cột Job còn bao nhiêu % ô unknown

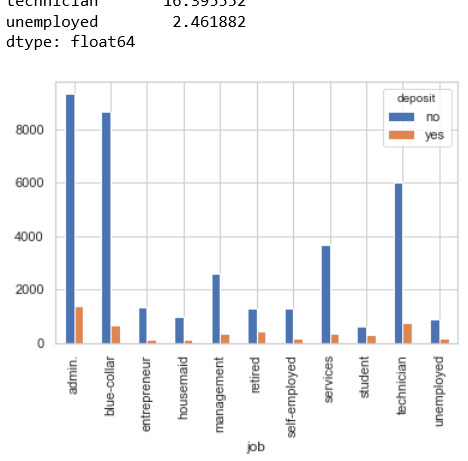
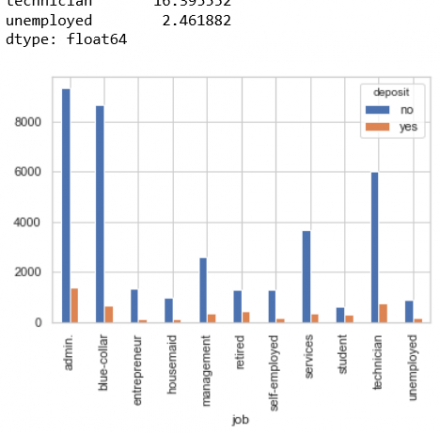
Kết quả giảm xuống từ 0.8% còn 0.5% ô unknown như vậy ta đã xử lý dc 1 phần mà ko làm mất đi dữ liệu. Ta tiếp tục xử lý phần còn lại này. Quan sát biểu đồ trên ta thấy trong data có phần lớn Khách hàng là admin, nên 0.5% ô unknown còn lại mình sẽ chuyển vào admin và được kết quả sau:

Như vậy ta đã xử lý sạch các ô unknown trong cột Job mà ko làm mất đi dữ liệu.
Kỳ này em sử dụng bộ data full hơn bộ trước, các bước xử lý là em tổng hợp được những ý hay của nhiều người phân tích trên mạng thành 1 bài riêng mà em cho rằng nó hợp lý hơn.
Đầu tiên là bộ data có hơn 41k dòng và 20 cột, Output vẫn là cột deposit mà các phần tử trong cột này chỉ có 2 giá trị là yes hay no, yes có ý nghĩa Khách hàng đồng ý gửi Tiết kiệm, no thì ngược lại
Sau khi check qua xem có ô nào bị trống ko có dữ liệu ko, và các Hàng của Cột có bằng nhau ko thì data thỏa mãn.
Tuy nhiên nhìn qua bảng data ta thấy có những ô là unknown, có nghĩa là ngay ô này ko có dữ liệu, nó tương đương với 1 ô trắng mà ta phải cần xử lý nó.
Em sẽ kiểm tra qua cột Job xem có bao nhiêu ô có unknown thì ra dc kết quả sau
Trong hình ta thấy các ô unknown trong cột Job này chiếm 0.8%, con số ko lớn lắm, tuy nhiên data là của quý nên ta ko tùy tiện loại bỏ các ô unknown này mà nên xử lý nó.
Em check tiếp cột education xem có bao nhiêu % là ô unknown
Kết quả là 4.2%, con số này bắt đầu thấy to to rồi vì mình có hơn 41k dòng, nếu ta quyết định xóa các ô unknown này thì ta sẽ mất đi hơn 1700 dòng dữ liệu, vì vậy ta cần xử lý nó mà ko xóa nó đi.
Đến đây thì ta check xem giữa Job và education có mối quan hệ như thế nào, lúc này mình check bảng ma trận của Job và education như sau:
Từ data ban đầu ta vẽ ra được bảng chỉ có Job và education, quan sát bảng trên ta thấy admin, management hầu hết là những người có bằng đại học, technician thì có bằng professional.course, service thì chủ yếu là high.school, từ đó mới có ý tưởng là khi ta biết Job(admin, management, technician, service) nhưng ko biết education thì ta có thể dự đoán ra người đó có education gì.
Vì vậy ở bước này quan sát cột unknown từ bảng trên thì ta cũng có thể tách 1 phần unknown vào các ô tương ứng, tương tự là ở dòng unknown cũng vậy.
Sau khi làm ta có kết quả sau:
Quan sát ta thấy cả dòng và cột unknow đã xuất hiện các phần tử 0, đây chính là các phần tử mà ta đã tận dụng và chuyển qua các ô tương ứng.Bây giờ ta checjk lại xem trong cột Job còn bao nhiêu % ô unknown
Kết quả giảm xuống từ 0.8% còn 0.5% ô unknown như vậy ta đã xử lý dc 1 phần mà ko làm mất đi dữ liệu. Ta tiếp tục xử lý phần còn lại này. Quan sát biểu đồ trên ta thấy trong data có phần lớn Khách hàng là admin, nên 0.5% ô unknown còn lại mình sẽ chuyển vào admin và được kết quả sau:
Như vậy ta đã xử lý sạch các ô unknown trong cột Job mà ko làm mất đi dữ liệu.
Attachments
-
 135,8 KB Đọc: 9
135,8 KB Đọc: 9 -
 29,8 KB Đọc: 11
29,8 KB Đọc: 11 -
 27,9 KB Đọc: 9
27,9 KB Đọc: 9 -
 42,8 KB Đọc: 9
42,8 KB Đọc: 9 -
 40,9 KB Đọc: 10
40,9 KB Đọc: 10 -
 30,2 KB Đọc: 9
30,2 KB Đọc: 9 -
 30,4 KB Đọc: 12
30,4 KB Đọc: 12